SSR não é uma moda técnica; é uma resposta pragmática a um fato desconfortável: a web moderna ficou dependente de JavaScript para entregar conteúdo, enquanto a indexação do Google continua sendo um processo com etapas, custos e limites. Quando você escolhe CSR (Client-Side Rendering) para um site que precisa rankear, você está apostando que o conteúdo “aparecer depois” será renderizado, entendido e indexado de forma consistente. Às vezes funciona. Em escala, com páginas profundas, com filtros, com performance irregular e com dependências externas, essa aposta costuma quebrar.
Este guia existe para resolver o que realmente importa: entender como o Google processa JavaScript, por que CSR falha em cenários reais, e por que SSR/SSG geralmente vencem quando o objetivo é indexação previsível e crescimento orgânico sustentável. O foco aqui não é repetir slogans (“SSR é melhor para SEO”), mas construir critério técnico e estratégico para decidir, implementar e auditar.
1) O que o Google realmente faz com JavaScript (e por que isso muda sua arquitetura)
Há um mito recorrente que confunde times inteiros: “o Google renderiza JavaScript, então está tudo certo”. A frase é verdadeira no sentido literal, mas enganosa no sentido operacional. Renderizar JavaScript não é um evento binário (“renderiza / não renderiza”); é uma cadeia de etapas com prioridades, filas, recursos e falhas possíveis. Para SEO, o que interessa é previsibilidade. E previsibilidade cai quando o conteúdo depende de execução do cliente.
O fluxo típico, simplificando, se parece com isto:
- Fetch: o Googlebot solicita a URL e recebe um HTML inicial.
- Indexação inicial: sinais básicos podem ser extraídos do HTML recebido (título, meta, links, canônico, cabeçalhos, estrutura).
- Renderização: em outra etapa, o Google pode usar um ambiente baseado em Chromium para executar JavaScript, carregar recursos e construir o DOM final.
- Indexação pós-render: com o DOM renderizado, o Google reavalia conteúdo, links inseridos via JS e dados estruturados, se disponíveis.
Na prática, “pós-render” é onde muitos sites CSR colocam o conteúdo principal. E aí começam os problemas: o que chega no primeiro HTML é quase vazio, e tudo depende da fase mais cara e menos garantida do pipeline. Quanto mais você empurra para o “depois”, mais você fica refém de gargalos e inconsistências. Essa lógica aparece com clareza na documentação do próprio Google sobre JavaScript e SEO, que descreve o processamento em etapas e boas práticas para evitar armadilhas comuns (JavaScript SEO basics).
Outro ponto que muita gente só aprende com perda de tráfego: não é só “o Google” que importa. Outros mecanismos, crawlers de redes sociais, parsers de mensageria, sistemas de preview, ferramentas de auditoria, e até recursos internos (cache, scraping para parceiros, integrações) consomem HTML inicial. CSR cria um universo paralelo: a página “real” existe no navegador do usuário, mas não existe para quem lê HTML puro. Isso é um problema de distribuição, não apenas de ranking.
O resultado: o debate SSR vs CSR, quando colocado como “preferência”, é superficial. O debate correto é: onde seu conteúdo nasce? No servidor (SSR/SSG), no build (SSG), ou no cliente (CSR)? A resposta define estabilidade de indexação, velocidade de descoberta, e custo de manutenção de SEO técnico.
2) SSR e indexação: por que ssr reduz risco no mundo real
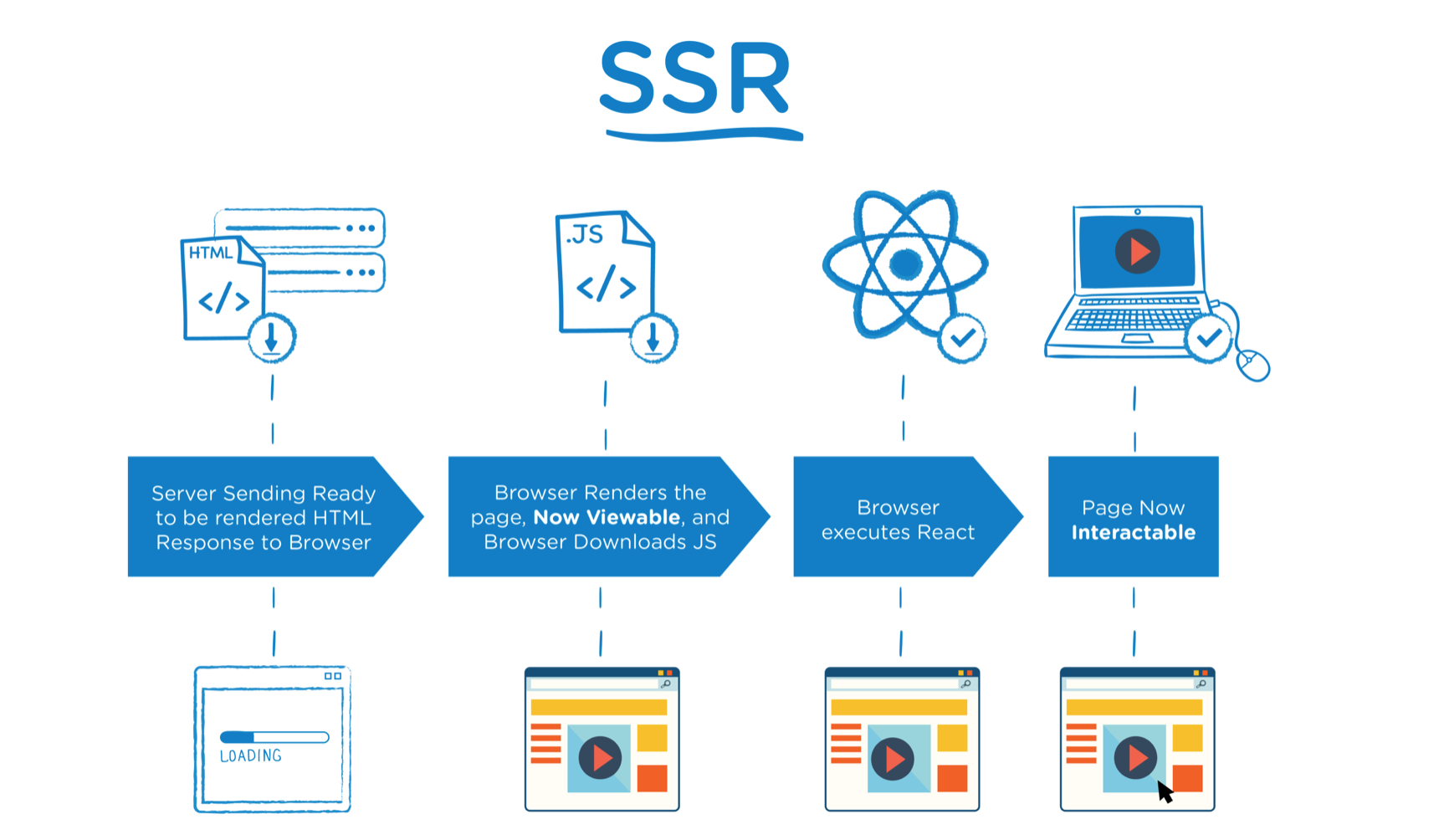
SSR (Server-Side Rendering) entrega HTML completo no primeiro response. Isso não significa que JavaScript desaparece; na maioria dos projetos modernos, o JS continua existindo para hidratação, navegação, componentes interativos e experiências ricas. A diferença é brutal: o conteúdo principal já está presente no HTML inicial. Para SEO, isso troca uma promessa (“o conteúdo vai aparecer”) por um fato verificável (“o conteúdo já está aqui”).
O Google consegue extrair sinais imediatamente, sem depender da fase de renderização. O ganho não é apenas “indexar mais”; é indexar com menos variância. Variância é inimiga de SEO porque ela gera sintomas difíceis de depurar: páginas que os usuários veem, mas o Google não; páginas que indexam e depois desindexam; snippets instáveis; canônicos ignorados; links internos que não são seguidos; e, em casos extremos, seções inteiras invisíveis para descoberta.
Em SSR, você reduz a superfície de falha:
- O conteúdo não depende de XHR para existir.
- O DOM inicial já contém cabeçalhos, parágrafos, links e breadcrumbs.
- Dados estruturados podem estar presentes desde o primeiro byte.
- O canônico e metas essenciais não ficam reféns de runtime.
Esse ponto, aliás, se cruza com uma mudança importante de postura do Google: “dynamic rendering” (servir uma versão pré-renderizada para bots e outra para usuários) foi por anos uma muleta comum para CSR. O próprio Google atualizou documentação para deixar claro que dynamic rendering é um workaround depreciado, não uma recomendação moderna. Isso aparece nas atualizações oficiais de documentação, que explicitam a revisão e o reposicionamento do tema (Search documentation updates).
O recado implícito é simples: se você precisa “enganar” o bot com um HTML alternativo, você está pagando uma dívida técnica permanente. SSR/SSG não “mascaram”; eles definem uma fonte de verdade única para usuários e crawlers.
Agora, o lado adulto da conversa: SSR não é mágica. Você pode fazer SSR e ainda assim falhar em SEO se entregar HTML incompleto, se quebrar canônicos, se gerar páginas duplicadas, se produzir conteúdo raso, se atrasar TTFB ao ponto de comprometer performance, ou se transformar hidratação em um pesadelo. SSR reduz risco de indexação, mas exige disciplina arquitetural.
SSR não é “render no servidor”, é “publicar conteúdo no servidor”
Times confundem SSR com “colocar um framework que suporta SSR”. O que interessa é: o conteúdo que você quer rankear está presente no HTML inicial? Se a resposta é “mais ou menos, porque ainda buscamos no cliente”, você está usando SSR como verniz. Um SSR real resolve o problema de origem: o servidor já conhece o que precisa entregar, seja via cache, seja via chamadas internas, seja via build incremental.
Exemplo concreto: um e-commerce com categoria “Tênis Masculino” que depende de uma chamada a um search backend. Em CSR puro, o HTML inicial chega com um esqueleto e depois preenche a lista de produtos no cliente. Se a API falha, se o tempo de resposta é alto, se o JS é bloqueado, ou se o render não conclui, o Google vê um vazio. Em SSR, o servidor consulta o backend e devolve a listagem no HTML. O cliente pode hidratar filtros e sorting, mas a base já está publicada.
3) Quando CSR falha na prática (e por que você só percebe tarde demais)
CSR funciona melhor em aplicações onde SEO não é prioridade: painéis internos, sistemas logados, produtos B2B com aquisição por outbound, experiências altamente dinâmicas onde páginas não precisam ser descobertas por busca. O problema é que muita gente aplica CSR como padrão universal, inclusive para conteúdo que depende de indexação. E então surgem falhas que não aparecem em “testes locais”, nem em uma navegação humana rápida.
A seguir, cenários recorrentes em que CSR quebra SEO de forma silenciosa, mesmo quando “o site parece perfeito” no navegador:
1) Conteúdo principal só existe após fetch (e o fetch é frágil)
Se a renderização depende de chamadas externas, você introduz variáveis: tempo de resposta, rate limit, bloqueios de IP, CORS mal configurado, erros intermitentes, dependência de cookies, headers, tokens, ou até geolocalização. Para o usuário, você pode ter retries e fallback. Para crawlers, não há paciência infinita. O resultado típico é indexação parcial: o Google indexa páginas “finas” (thin) e trata seu site como de baixo valor, não porque o conteúdo é ruim, mas porque ele não está sempre disponível.
2) Rotas e parâmetros geram explosão de URLs e duplicidade
SPA com CSR costuma incentivar filtros via querystring, hash, estados internos e combinações quase infinitas. Sem controle rigoroso de canonicalização e noindex, você cria duplicatas, canibaliza sinais e desperdiça crawl budget. O Google não “odeia” parâmetros, mas ele exige coerência: URLs diferentes precisam significar coisas diferentes; o canônico precisa ser estável; e você precisa declarar o que merece indexação. Em CSR, esses sinais muitas vezes são aplicados por JS, tarde demais ou de forma inconsistente.
3) Links internos não aparecem no HTML inicial
Descoberta é a base do SEO. Se menus, breadcrumbs, links de paginação, links de produtos relacionados e links de categorias só surgem após render no cliente, você reduz a capacidade do Google de descobrir seu grafo interno cedo. Em sites grandes, isso cria “ilhas” de URLs que dependem de navegação renderizada para existir. Esse é um dos motivos pelos quais CSR pode até indexar a home, mas falha em indexar profundidade.
4) Meta tags e canônico definidos em runtime
Há projetos onde o título, meta description, hreflang e canônico são definidos por scripts que rodam após a renderização. Em alguns casos, o Google pode capturar; em outros, ele pode priorizar o que veio no HTML inicial. A variância aumenta. E variância em canônico e hreflang costuma virar caos: páginas erradas rankeando, regiões erradas recebendo tráfego, e clusters de duplicidade que drenam autoridade.
5) Erros de status e redirecionamentos “mascarados”
CSR frequentemente usa o padrão “sempre responde 200 e o app decide o que mostrar”. Para SEO, isso é perigoso. Páginas que deveriam ser 404 retornam 200 com uma tela “não encontrado” renderizada via JS. O Google aprende que você tem conteúdo de baixa qualidade e pode indexar páginas inexistentes. O próprio Google reforçou em atualizações recentes de documentação nuances sobre renderização em páginas com códigos não-200 e implicações de processamento, justamente porque isso gera confusão operacional em ambientes com JS (Search Central Blog e referências de atualização de documentação citadas em cobertura de mudanças).
6) Performance e Core Web Vitals degradados pela hidratação
CSR tende a empurrar muito trabalho para o cliente: parse de bundles, execução de framework, carregamento de dependências, render inicial e, só então, conteúdo. Em mobile de entrada, isso é dramático. Mesmo que ranking não seja “só CWV”, a realidade é que páginas lentas afetam comportamento do usuário, eficiência de crawl e estabilidade de renderização. SSR/SSG permitem entregar conteúdo significativo cedo, e tratar interatividade como etapa posterior, mais controlável.
O ponto central: CSR falha não por dogma, mas porque cria um sistema onde SEO depende de condições ideais. Na web, condições ideais não existem com consistência. A única estratégia robusta é reduzir dependência do “depois”.
4) SSR vs CSR no SEO: o comparativo que importa (incluindo ssr em projetos grandes)
Comparar SSR e CSR como se fossem caixas fechadas é perder nuance. O que você quer é mapear trade-offs e escolher uma arquitetura que minimize risco e maximize capacidade de evolução. Para SEO, há cinco dimensões que decidem o jogo: indexação, descoberta, performance percebida, governança de URLs e custo operacional.
Indexação e qualidade do conteúdo indexável
SSR entrega HTML completo, então o Google pode indexar com base no conteúdo primário desde a primeira visita. CSR exige renderização para chegar ao conteúdo, e você passa a depender da etapa mais cara do pipeline. Em sites pequenos, isso pode ser irrelevante. Em sites com milhares de URLs, vira um multiplicador de risco.
Descoberta e arquitetura de links
SSR favorece a existência de links internos no HTML inicial, o que acelera descoberta e reforça hierarquia. CSR costuma esconder links atrás de componentes e estados de runtime. Se sua estratégia de SEO depende de páginas profundas (categorias, facetas, artigos em clusters), SSR tende a ser mais confiável.
Performance percebida e “conteúdo útil cedo”
SSR geralmente melhora a sensação de carregamento porque o usuário vê conteúdo antes. O desafio é não transformar SSR em servidor lento. Se seu backend é pesado, SSR pode piorar TTFB. O caminho maduro é cache, edge, streaming, e segmentação de interatividade. CSR, por sua vez, pode ter TTFB baixo e ainda ser lento no “tempo até conteúdo real” porque o cliente precisa executar tudo.
Governança de URLs: canônicos, parâmetros, internacionalização
SSR facilita a construção de HTML coerente por URL, incluindo canônico, hreflang, meta robots, e dados estruturados por rota. CSR pode fazer isso, mas a chance de inconsistência cresce, especialmente quando há navegação interna sem reload, estados, e “rotas virtuais”. Em organizações onde SEO é responsabilidade compartilhada entre times, governança simples costuma vencer.
Custo operacional: engenharia e manutenção
CSR parece mais simples no início, mas fica caro quando você começa a adicionar “camadas de SEO”: prerender, dynamic rendering, correções de head, hacks de status code, validações e auditorias específicas. SSR/SSG demandam investimento inicial maior, mas reduzem a necessidade de remendos e diminuem o custo de explicar ao Google o que a sua página já deveria dizer por si mesma.
Uma síntese honesta: CSR é viável quando SEO não é central ou quando o site é pequeno e controlado. Em projetos de conteúdo, e-commerce, marketplace, SaaS com páginas públicas de aquisição, e qualquer operação que precise de previsibilidade de indexação, SSR/SSG costumam vencer. E não por “preferência”, mas por engenharia de risco.
5) SSR, SSG, ISR e hidratação: o ecossistema real além do debate “SSR vs CSR”
Se você ficou apenas em SSR vs CSR, você está perdendo o melhor do jogo moderno: arquiteturas híbridas. Hoje, o que mais aparece em projetos maduros é a combinação de técnicas para equilibrar SEO, performance e custo.
SSG (Static Site Generation): conteúdo pronto no build
SSG gera HTML estático no momento do build. Para SEO, é frequentemente excelente: HTML completo, rápido, previsível, fácil de cachear. O limite é óbvio: conteúdo que muda o tempo todo vira um problema de rebuild. Para blogs, documentações, páginas institucionais e landing pages relativamente estáveis, SSG é uma arma de simplicidade.
ISR (Incremental Static Regeneration): estático com atualização inteligente
ISR tenta unir o melhor dos dois mundos: você publica estático, mas permite regenerar páginas sob demanda ou em intervalos. Isso é útil para páginas de categoria, páginas de produto e conteúdo que muda com frequência moderada. Do ponto de vista de SEO, ainda é HTML completo na entrega. Do ponto de vista operacional, você reduz a pressão de SSR em tempo real.
SSR “com hidratação” (o padrão de frameworks modernos)
O padrão mais comum em frameworks modernos é: o servidor envia HTML inicial e o cliente hidrata para interatividade. A hidratação é um ponto de risco: se for lenta, o usuário vê conteúdo, mas interações travam; se for pesada, você perde Core Web Vitals; se for mal planejada, você carrega JS desnecessário. Ainda assim, do ponto de vista de indexação, é uma evolução enorme em relação ao CSR puro.
Ilhas de interatividade (islands architecture)
Uma abordagem mais refinada é limitar JS apenas onde existe interatividade real. O resto é HTML. Isso reduz bundle, melhora performance e mantém SEO forte. Em sites editoriais e páginas de aquisição, essa mentalidade costuma produzir ganhos imediatos: menos dependência de framework para tudo, mais foco em conteúdo e experiência.
Quando alguém diz “SSR/SSG vence”, geralmente está apontando para esta família de abordagens: publicar HTML como fonte primária e usar JS como complemento, não como origem do conteúdo. Essa é a inversão decisiva.
6) Checklist avançado: como auditar indexação e provar se CSR está te sabotando (com foco em ssr)
Não existe decisão madura sem diagnóstico. Antes de migrar, você precisa medir. E medir, aqui, não é olhar o site no navegador. É validar o que chega sem JavaScript, o que o Google enxerga, e o que se perde entre HTML inicial e DOM renderizado.
1) Compare “View Source” vs DOM final
Abra a página e use “Ver código-fonte” (HTML inicial). Em paralelo, inspecione o DOM. Procure:
- O conteúdo principal (texto, headings) está no HTML inicial?
- Links internos importantes aparecem no source?
- Dados estruturados estão no source, ou só surgem no DOM?
- O canônico e metas essenciais estão presentes desde o início?
Se o HTML inicial é um esqueleto vazio, você já sabe o essencial: seu SEO depende de renderização. A pergunta passa a ser: isso está funcionando de forma consistente? E “consistente” exige testes.
2) Use o Search Console para validar renderização e cobertura
A Inspeção de URL no Search Console mostra se a página está indexada, qual canônico o Google escolheu, e oferece um retrato do que foi processado. O valor aqui não está em um print; está em padrões. Se páginas semelhantes têm resultados diferentes, você tem variância estrutural.
3) Teste com ferramentas que simulam renderização e sem renderização
Em auditorias técnicas, vale rodar crawls em dois modos: sem render e com render. Quando o gap entre os dois é enorme, você descobriu um problema de dependência: seu site “existe” apenas sob certas condições. Em operações grandes, esse gap costuma se traduzir em perda de indexação de long tail, facetas e profundidade.
4) Verifique bloqueios de recursos (robots, headers, CDNs)
Bloquear JS/CSS em robots.txt pode impedir renderização correta. Headers de segurança mal configurados podem quebrar carregamento. CDNs podem servir versões inconsistentes. O Google, na própria documentação de JS, reforça a necessidade de permitir acesso a recursos essenciais e evitar bloqueios que impeçam renderização completa (guia oficial).
5) Audite status codes reais
Páginas “não encontradas” precisam retornar 404 de verdade. Páginas removidas precisam de 410 ou redirect adequado. Se sua SPA devolve 200 para tudo e o app decide a mensagem, você está produzindo lixo indexável. Isso destrói confiança algorítmica ao longo do tempo.
6) Avalie a arquitetura de dados estruturados
Schema inserido via JS pode funcionar, mas é mais confiável quando sai no HTML inicial. Se o seu SEO depende de rich results, consistência é prioridade. O caminho prático: dados estruturados no servidor para páginas críticas, com validação contínua.
Uma regra simples, difícil de aceitar quando o time ama CSR: se você precisa de uma bateria de ferramentas para “provar que o Google enxerga”, provavelmente você já perdeu a simplicidade que SEO gosta. SSR/SSG devolvem essa simplicidade porque o conteúdo é verificável em qualquer contexto que consuma HTML.
7) Estratégia de migração sem trauma: como sair de CSR e chegar em SSR/SSG com segurança
O erro clássico em migração de renderização é tratar como “troca de tecnologia”. Não é. É uma mudança de fonte de verdade do conteúdo. E isso impacta roteamento, status codes, canônicos, internacionalização, performance e observabilidade. Uma migração bem feita é incremental, baseada em risco e em páginas que pagam a conta.
Comece pelas páginas que geram aquisição
Não tente “SSRizar” o app inteiro. Priorize:
- Páginas de categoria e listagem que sustentam tráfego.
- Páginas de produto/serviço com intenção comercial alta.
- Conteúdo editorial que forma clusters e atrai long tail.
- Landing pages de campanha e páginas institucionais.
Essas páginas devem entregar HTML completo e estável. Interatividade pode ser progressiva. O objetivo é: reduzir dependência de JS para o que precisa rankear.
Defina padrões de URL e canonicalização antes de tocar no framework
Se você tem filtros, facetas e parâmetros, estabeleça regras: o que indexa, o que não indexa, qual é o canônico por família de URL, e como paginação se comporta. Em CSR, times costumam “adiar” isso. Em SSR/SSG, você precisa declarar desde o começo, ou sua migração vira geradora de duplicidade.
Garanta parity de conteúdo e mapeamento de redirects
Mudou rota? Redireciona. Mudou slug? Redireciona. Mudou estrutura de categorias? Redireciona. Migração de renderização frequentemente vem acompanhada de refactor de rotas; se você não tratar isso como projeto de SEO técnico, você perde sinais acumulados.
Performance é parte do SEO técnico, não um bônus
SSR pode aumentar TTFB se você renderiza tudo em tempo real sem cache. O caminho maduro é combinar cache agressivo, edge quando fizer sentido, e degradação elegante. Pense em SSR como “publicar HTML”, não como “calcular tudo ao vivo”.
Observabilidade: logue e monitore como se fosse receita
Quando você muda a forma de renderizar, você muda pontos de falha. Monitore:
- Taxa de 5xx e 4xx por template/rota.
- Tempo de resposta (TTFB) e percentis.
- Erros de hidratação no cliente.
- Diferenças entre HTML servido e esperado.
- Quedas de páginas indexadas e padrões por diretório.
SEO não é apenas “ser indexado”; é ser indexado com estabilidade e ganhar espaço progressivamente. SSR/SSG criam as condições para isso porque reduzem o número de variáveis invisíveis.
Sobre “dynamic rendering”: trate como último recurso, não como estratégia
Se você está preso em uma SPA enorme e precisa de um paliativo, prerender e soluções intermediárias podem existir. Mas a direção recomendada hoje, inclusive pela evolução da documentação do Google, é reduzir dependência de workarounds e publicar conteúdo de forma nativa, com HTML consistente. Quando uma prática vira “depreciada” na documentação, ela tende a virar dívida com prazo curto (atualizações oficiais).
O caminho que funciona na prática é: migrar gradualmente páginas públicas críticas para SSR/SSG, manter o app logado em CSR se fizer sentido, e construir uma camada de governança de SEO técnico que impeça regressões. Essa separação (público indexável com HTML robusto, privado com CSR) costuma ser o modelo mais eficiente em organizações que precisam tanto de UX rica quanto de aquisição orgânica consistente.
No fim, o debate não é filosófico. É operacional. Se seu negócio depende de tráfego orgânico, você quer reduzir aposta e aumentar controle. E controle, na web, começa com algo simples: entregar conteúdo no HTML inicial. É por isso que SSR e SSG “geralmente vencem” — não porque são superiores em abstração, mas porque são superiores em confiabilidade de indexação, governança e capacidade de escalar sem surpresas.
::contentReference[oaicite:0]{index=0}