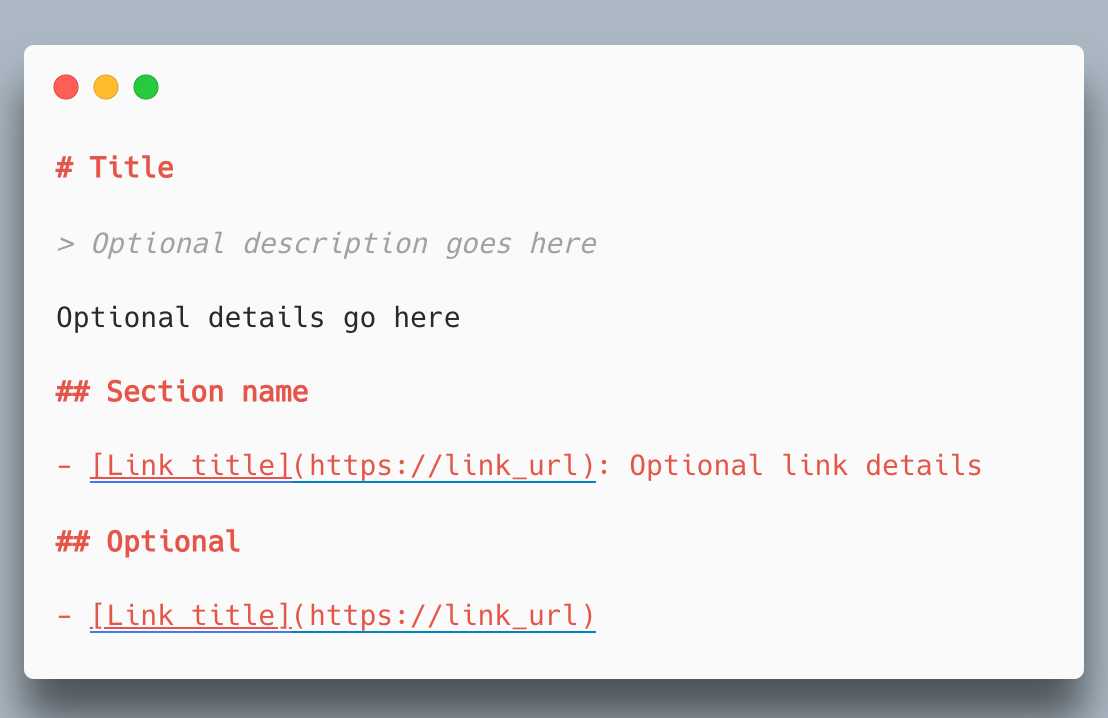
Repare no que esse exemplo faz: ele separa “fonte primária” de “how-to” e de “histórico”. Isso reduz o risco de um agente citar um changelog antigo como se fosse a regra atual, ou usar um post de blog como definição oficial. Em muitos nichos, essa distinção é a diferença entre uma resposta correta e uma resposta confiante e errada.
Também é recomendável incluir a versão “llms-full.txt” em alguns contextos, quando você quer oferecer uma compilação mais extensa (por exemplo, documentação completa em um único arquivo). Mas isso deve ser tratado com cautela: conteúdo demais em um único arquivo pode virar desperdício e aumentar o risco de o agente puxar trechos fora de contexto. A versão “full” é útil quando você sabe que o consumidor é um pipeline de ingestão controlado, e não um agente genérico que faz scraping oportunista.
Quando usar llmstxt: sinais claros de que o arquivo vai trazer retorno (e quando é só distração)
O llmstxt faz sentido quando existe um problema real de consumo por IA e por agentes: volume alto de páginas, navegação complexa, documentação crítica, mudanças frequentes de regras, e necessidade de respostas consistentes. Em outras palavras, ele paga a conta quando “ser bem interpretado” é uma parte do seu funil, seja para aquisição (ser citado em respostas), seja para retenção (reduzir tickets), seja para autoridade (ser a fonte que os agentes escolhem).
Se você administra um blog pequeno, com poucas páginas e conteúdo estável, o retorno tende a ser marginal. O seu esforço deve ir para arquitetura, cluster semântico, qualidade editorial, velocidade e indexação. O llmstxt pode existir, mas não deve consumir energia que deveria estar na produção de conteúdo e na consolidação de entidades.
Agora, existem cenários em que o llmstxt é quase obrigatório, mesmo que você não “acredite” na moda. Documentação técnica é o primeiro. Sites de produtos SaaS, APIs, bibliotecas, plataformas de integração e bases de conhecimento sofrem com a mesma dor: o usuário não quer ler quarenta páginas para descobrir o endpoint certo. Ele pergunta para um assistente. Se o assistente erra, o usuário culpa você, não o modelo. Portanto, você tem incentivo direto em reduzir erro de interpretação. Um llmstxt bem feito aponta os documentos corretos e pode aumentar a consistência do que é recuperado.
Outro cenário: empresas com compliance e definições formais (termos, políticas, padrões de uso). Um agente pode citar uma política antiga, uma versão cached ou um post interpretativo como se fosse regra oficial. Se você sinaliza “fonte primária” e organiza o caminho de leitura, você reduz o risco de desinformação atribuída à sua marca. Isso não elimina o risco, mas ajuda a orientar a recuperação de contexto.
Há também um uso comercial e menos óbvio: páginas que você quer que sejam “o núcleo explicativo” do seu posicionamento. Em mercados competitivos, as respostas de assistentes tendem a ficar genéricas. Quem tiver páginas pilares bem definidas, com linguagem precisa e sem ruído, aumenta a chance de ser referenciado. O llmstxt, nesse caso, funciona como uma forma de declarar: “se você vai me entender, comece por aqui”.
Em contrapartida, é distração quando vira “projeto paralelo” sem amarração no conteúdo. Se você vai criar llmstxt, mas não tem páginas pilares fortes, não tem definições coerentes, não tem consistência editorial, ele vira mais um arquivo para manter, sem impacto real. Em SEO e autoridade, manutenção sem retorno é veneno: dá sensação de progresso e adia decisões difíceis, como cortar conteúdo fraco, consolidar tópicos duplicados, reescrever páginas fundamentais e construir uma narrativa de marca.
Um critério rápido e honesto: se você consegue apontar, em uma frase, quais são as 10 URLs que definem a compreensão do seu negócio e do seu produto, você está pronto para llmstxt. Se você não consegue, o problema não é o arquivo; é a falta de “coluna vertebral” editorial.
llmstxt na prática: implementação em WordPress, governança editorial e integração com SEO tradicional
Em WordPress, a implementação técnica do llmstxt é simples: publicar um arquivo llms.txt na raiz do site. O desafio real é governança. Quem decide o que entra? Com que frequência atualiza? Como impedir que o arquivo vire um cemitério de links? E como manter coerência com o restante do stack de SEO?
Do ponto de vista operacional, há três caminhos comuns. O primeiro é manual: você cria o arquivo e atualiza quando mudanças importantes acontecem. Funciona bem para sites pequenos e médios, desde que exista disciplina editorial. O segundo é semi-automatizado: você gera uma base a partir de categorias, taxonomias e páginas marcadas como “pilar”, e revisa manualmente antes de publicar. O terceiro é automatizado com regras: o CMS exporta um llmstxt com base em “tipo de conteúdo”, “prioridade editorial” e “estado de publicação”, o que é útil para documentação ou help centers.
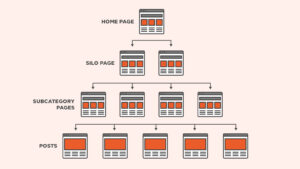
Em WordPress, a abordagem semi-automatizada costuma ser a melhor. Você define uma taxonomia ou um campo (ACF, por exemplo) para marcar páginas “fonte primária”, “how-to” e “secundário”. A partir disso, você gera um arquivo com a hierarquia correta. O que não pode acontecer é deixar o llmstxt refletir a estrutura do menu do site. Menu é uma decisão de navegação humana, muitas vezes influenciada por marketing e campanha. O llmstxt deve refletir a estrutura de conhecimento: conceitos, definições, guias, referência.
Outro detalhe: se você usa internacionalização, o llmstxt precisa ser coerente com seu hreflang e com a sua estratégia de idioma. Você pode publicar um llms.txt por idioma (em subdomínios ou subpastas), ou publicar um arquivo que aponta explicitamente para as versões por idioma. Não existe uma regra única; o que existe é o risco de confundir agentes com páginas em língua errada. Se o seu público é brasileiro, o seu llmstxt deve priorizar páginas em português e manter consistência.
Integração com SEO tradicional não é opcional. O llmstxt deve apontar para URLs canônicas, não para variações com parâmetros, não para páginas paginadas, não para versões AMP antigas, não para duplicatas. Ele também deve respeitar a sua arquitetura de internal linking: se uma página é central o bastante para estar no llmstxt, ela deveria estar bem linkada no site e suportada por clusters semânticos. Caso contrário, você cria uma dissonância: “para IA esta página é central; para humanos e para SEO, ela é periférica”. Esse tipo de incoerência costuma indicar que você ainda não decidiu a hierarquia real do seu conteúdo.
Na prática, um bom llmstxt em WordPress costuma vir acompanhado de três ajustes: (1) revisão de headings e estrutura semântica das páginas apontadas; (2) criação de versões “limpas” para páginas críticas (quando o tema é técnico e o site é carregado de plugins e blocos); (3) atualização sistemática de páginas pilares para que o arquivo aponte para conteúdo que realmente representa a visão atual.
Se você quiser elevar o nível, inclua um bloco curto de “política editorial” dentro do llmstxt: como o conteúdo é atualizado, onde ficam definições oficiais, como lidar com histórico. Isso não é “comando” para o modelo; é contexto. Contexto reduz interpretação errada. E, no universo de respostas geradas, a diferença entre “texto sem contexto” e “texto com contexto” é enorme.
Riscos, limitações e o ponto cego que quase ninguém menciona sobre llmstxt
O risco mais óbvio é superestimar adoção. Você publica o arquivo e espera impacto imediato. Nem todo sistema vai usar. Alguns vão ignorar. Outros podem consumir em cenários específicos. O retorno não é garantido, e você precisa tratar isso como um componente de um sistema maior de visibilidade, não como um hack.
O risco mais perigoso é o oposto: assumir que, porque você publicou llmstxt, agora “controla” o que modelos fazem. Não controla. Um agente pode seguir o arquivo ou pode fazer scraping direto do site, pode usar caches, pode usar datasets e pode buscar suas páginas por outros sinais. O llmstxt é um convite, não um portão. Ele melhora a probabilidade de consumo correto, mas não impõe comportamento universal.
Existe também um risco editorial. Ao declarar “estas são as páginas essenciais”, você expõe incoerências internas. Se as suas páginas pilares são mal escritas, contraditórias ou genéricas, você acelera a difusão desse problema. Um llmstxt pode aumentar a taxa de recuperação de conteúdo, e isso é bom quando o conteúdo é sólido. Quando não é, você amplifica uma fraqueza.
Outro ponto cego: o llmstxt pode incentivar uma arquitetura “IA-first” mal desenhada, em que você cria páginas artificiais só para servir a modelos, sacrificando experiência humana. O caminho correto é convergência: páginas que funcionam para humanos e, por consequência, funcionam melhor para agentes. Quando for necessário criar versões limpas (Markdown, por exemplo), elas devem ser derivadas do conteúdo oficial, não paralelas e divergentes. Duas fontes divergentes criam caos e aumentam a chance de o agente escolher a errada.
Há ainda a questão de atualização. Em ambientes onde regras mudam rápido (preço, políticas, integrações, requisitos), um llmstxt desatualizado é pior do que não ter. Ele dá uma falsa sensação de “mapa confiável”, mas aponta para documentos velhos. Portanto, se você não tem processo de revisão, limite o escopo do arquivo: priorize páginas estáveis e trate conteúdo volátil como volátil, com avisos claros.
Um aspecto menos comentado é a relação entre llmstxt e reputação de fonte. Em respostas geradas, modelos e agentes tendem a preferir fontes percebidas como oficiais, consistentes, estáveis e claras. O llmstxt ajuda a declarar oficialidade, mas a reputação vem do ecossistema: backlinks, menções, consistência temporal, autoria e confiabilidade. Se você quer que o seu conteúdo seja usado por agentes, você precisa construir EEAT de forma real: autores identificáveis, experiência demonstrável, atualização transparente, exemplos verificáveis, e um padrão editorial que resiste ao tempo.
Por fim, existe uma limitação filosófica: agentes não buscam apenas “texto”. Eles buscam intenção. Se o seu conteúdo é escrito para ranquear e não para instruir, ele tende a ser cheio de “gordura”: introduções longas, frases vagas, listas genéricas. Para humanos, isso já é cansativo. Para agentes, é ruído. O llmstxt não corrige isso. Ele apenas aponta. O conteúdo precisa merecer ser apontado.
Métricas, exemplos concretos e como pensar llmstxt como parte de uma estratégia de autoridade (sem abandonar SEO)
Se você implementa llmstxt com seriedade, você precisa de critérios de sucesso que não dependam de fé. O problema é que “IA” ainda é um canal com métricas menos padronizadas do que busca tradicional. Mesmo assim, dá para medir sinais indiretos e construir um ciclo de melhoria.
Primeiro, revise seu tráfego de referência e logs de servidor. Dependendo do seu stack, você pode identificar user-agents de ferramentas e crawlers relacionados a IA, ou padrões de acesso a páginas de documentação e versões em Markdown. Nem sempre é transparente, mas padrões existem: aumento de hits em páginas pilares, crescimento de consumo de rotas “clean”, concentração de acessos em conteúdos que você listou no llmstxt. O objetivo é perceber se o arquivo está influenciando o comportamento de coleta.
Segundo, monitore menções em respostas e citações. Isso é mais trabalhoso, mas dá para fazer de modo sistemático: queries de marca e tópicos em diferentes assistentes, em janelas de tempo fixas, registrando se suas páginas aparecem como fonte. Não se trata de obcecar com “ser citado”, mas de avaliar se o seu conteúdo está sendo recuperado quando o tema é consultado. Um llmstxt bem feito, aliado a páginas pilares fortes, tende a aumentar a consistência de recuperação, mesmo que não mude tudo da noite para o dia.
Terceiro, avalie impacto em suporte e onboarding. Em produtos e serviços, a IA virou interface de busca. Se seus clientes usam assistentes para tirar dúvidas, qualquer aumento de precisão reduz ticket. Você pode medir isso via redução de chamados repetitivos, aumento de resolução no primeiro contato e melhoria de NPS de documentação. Aqui o llmstxt atua indiretamente: ele melhora a chance de o usuário receber uma resposta correta quando pergunta para um agente, o que diminui fricção no uso do seu produto.
Agora, exemplos práticos. Imagine um site que vende uma plataforma de integração e possui dezenas de páginas sobre “API”, “webhook”, “autenticação”, “rate limit”, “erros”. Sem llmstxt, um agente pode cair em um post antigo sobre autenticação, citar um endpoint descontinuado e induzir o usuário ao erro. Com llmstxt, você aponta explicitamente para “Autenticação v2 (fonte primária)” e para “Erros e troubleshooting (atualizado)”, separando “changelog” como histórico. Isso não garante obediência, mas melhora muito a probabilidade de o contexto montado ser o correto.
Outro exemplo: um portal editorial que publica guias e comparativos. O agente tende a preferir listas curtas e definições claras. Se você tem um guia pilar que define termos, critérios e metodologia, e dezenas de posts satélites, o llmstxt pode destacar o pilar como “metodologia oficial” e listar satélites como leitura secundária. Assim, mesmo que o agente recupere um satélite, ele tem um ponto de ancoragem conceitual para reduzir alucinação e generalização indevida.
O que amarra tudo é estratégia de autoridade. Autoridade não é “aparecer” em IA; é ser a referência quando o assunto importa. A forma mais segura de construir isso continua sendo a mesma: conteúdo pilar com profundidade real, cluster semântico coerente, atualização responsável, autoria forte, provas (exemplos, dados, procedimentos) e consistência editorial. O llmstxt é um componente novo porque o canal mudou, mas a lógica é antiga: você define a melhor versão da sua verdade e facilita o acesso a ela.
Para fechar com pragmatismo: se você quer expor conteúdo para crawlers e agentes de IA com regras claras sem substituir SEO tradicional, trate o llmstxt como um “índice editorial para consumo por linguagem”. Publique, mantenha pequeno e intencional, conecte a páginas que merecem ser fonte, e use o processo de criação do arquivo para corrigir o que realmente trava sua autoridade: páginas fracas, duplicação, falta de definições e ausência de um núcleo canônico de conhecimento.
- Referência de especificação e exemplos: llmstxt.org
- Contexto do anúncio e proposta original: Answer.AI (Jeremy Howard)
- Discussões sobre adoção, utilidade e ceticismo: Mintlify
- Integrações e adoção em plataformas de documentação: GitBook
- Convenção alternativa para instruções inline: Vercel
::contentReference[oaicite:0]{index=0}